
Meet the DF Score: Your Deployment Report Card


You’ve built an amazing AI model. You’ve tuned it. You’ve tested it. Now you need to release it, and that’s where many enterprises hit a wall.
The DF score is a single formula that’s used to measure exactly how much pain your deployment process causes. It’s the operational truth that many try to avoid: how long deployments take, how often they break, and how often you have to hit undo. If you’re spending more time rolling back releases than shipping features, your DF score is screaming at you.
The DF score as a formula expressed like this:
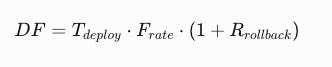
In plain English: The DF score equals operational friction, instability, or deployment burden associated with releasing software or AI systems into production.
How to read the formula
Here’s what each part of the formula means:
(T_{deploy}) is the deployment time, representing average deployment duration, deployment effort, release cycle time or operational coordination cost. In other words, longer deployments increase operational burden.
(F_{rate}) represents the failure rate associated with deployments. There are many examples of failures including failed releases, deployment incidents, outages, broken builds and post-release defects. Higher failure rates imply lower operational reliability.
(R_{rollback}) means the rollback rate. This part of the formula measures how often deployments must be reversed, reverted, or patched after release. Frequent rollbacks signal instability, insufficient testing, weak release governance, or architectural fragility.
((1 + R_{rollback})) is the deployment burden when rollback activity increases. The multiplier rewards stability: low rollback frequency compounds gains, while instability compounds losses.
Overall Meaning
The formula combines three realities of a deployment process—how long deployments take, how often they fail, and how often you roll them back—into a single score. A low score means fast, reliable deployments with few problems. A high score means slow deployments, frequent failures, and constant rollbacks—a sign that your process needs work.
Why AI and Enterprise Teams Need a Deployment Friction Metric
This metric helps DevOps, AI, and MLOps teams track deployment maturity and reliability. It flags the real problems: brittle pipelines, unstable practices, scaling bottlenecks, weak testing, and accumulating operational debt—giving you a single number to watch instead of scattered signals across your infrastructure.
The AI Deployment Crisis Is Real
Enterprise AI projects are failing at scale—not because the models are bad, but because the operational infrastructure can’t handle them. LinkedIn is full of stories: teams that trained beautiful models but couldn’t deploy them safely. Articles in Harvard Business Review, MIT Sloan, and the trade press all point to the same bottleneck: deployment friction. Organizations are spending millions on AI initiatives only to get stuck in the production phase, wrestling with brittle pipelines, insufficient testing, and constant rollbacks that consume engineering resources and delay time-to-value.
The DF score cuts through the noise. Instead of tracking deployment time, failure rates, and rollback frequency as separate metrics—easy to ignore individually—it combines them into a single operational truth. A high DF score is a red flag that your organization isn’t ready to scale AI in production. It’s a signal that you’re accumulating technical debt faster than you’re delivering value. For enterprises serious about AI, the DF score matters because it measures what actually matters: can you reliably get your AI systems into production, keep them stable, and iterate without breaking things?
The companies excelling at AI share a common trait: they've mastered the operational side. The best model means nothing without the reliability to deploy it, iterate on it, and scale it. That's what a low DF score really measures.
What’s your DF score? If you’d like to talk through how to measure and improve deployment friction at your organization, let me know. Email me.
the friction-as-signal frame lands. the hardest deployment edge case i hit wasn't a slow release — it was the model being right for the wrong reason. metrics looked clean, but the collector had biased the eval sample. clean DF score, broken pipeline. question: does your framework surface "correct by coincidence," or only operational drag?